
Dalam melakukan klasifikasi atau deteksi objek, biasanya membutuhkan banyak data gambar, untuk mendownload gambar pada google image secara manual tentu membutuhkan banyak waktu dan membosankan. Sehingga perlu ditemukan solusi untuk memanfaatkan google image sebagai saran membuat dataset yang baik dan cepat. kita menggunakan program javascript dan python untuk mengumpulkan gambar dari google image. Pada program javascript ditujukan untuk mengambil URL gambar yang ada di google image kemudian program python yang melakukan eksekusi untuk mendownload gambar tersebut.
Program ini digunakan untuk mengambil URL pada google image dengan menggunakan library javascriptscript yaitu jQuery. jQuery adalah perpustakaan Javascript yang cepat, kecil, dan kaya fitur. jQuery membuat hal-hal seperti traversal dan manipulasi dokumen HTML, penanganan event, animasi, dan Ajax lebih sederhana dengan API (application programming interface) yang mudah digunakan yang bekerja di banyak browser. Dengan kombinasi fleksibilitas dan kemampuan besar, jQuery telah mengubah cara jutaan orang menulis JavascriptScript. Sebelum kita mencoba silahkan download terlebih dahulu codenya di GitHub saya.
1. Langkah pertama dalam menggunakan google image untuk mengumpulkan data adalah menuju ke google image dan memasukkan query. Dalam hal ini kita akan menggunakan istilah query "Penghapus"

2. Kemudian menggunakan javascripts untuk mengumpulkan URL gambar yang kemudian nantinya akan didownload menggunakan program python. Sebelumnya kita menentukan batas URL yang akan didownnload. Javascriptscript di input pada console yang ada pada developer tools pada browser, kita menggunakan software google chrome.

Dalam javascript untuk membuat variabel dapat menggunakan var dan tanpa menggunakan var. Kita membuat variable script dengan membuat element yang diberi tagName yaitu script. tagName adalah String yang menentukan jenis elemen yang akan dibuat. Dalam dokumen HTML, document.createElement() method menciptakan element HTML yang ditentukan oleh tagName, atau HTML Unknown Element jika tagName tidak dikenali. Kemudian script.src yaitu untuk menggunakan library jQuery dan SP.RequestExecutor dimana script.src ini dimasukkan kedalam variable script. Untuk kode baris keempat adalah cara untuk memasukkan element ke dalam DOM (Document Object Model) secara dinamis. Dalam kasus ini disisipkan di bagian akhir <head>, dan "script" adalah string yaitu tagName.
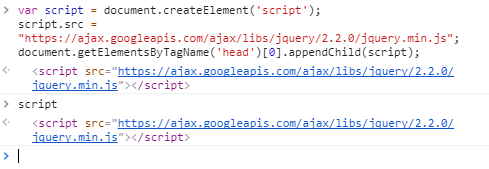
Selanjutnya untuk kode terakhir yaitu untuk melakukan pengambilan URL pada google image.

Agar file mudah diolah pada program python maka semua URL yang didapatkan akan disimpan kedalam satu file yaitu .txt. Setelah itu akan dilakukan proses pada program python untuk mendownload gambar pada URL tersebut.

Pada baris pertama yaitu membuat urls tersusun berurutan membentuk array dengan setiap URL akan ditulis pada baris baru. Jadi pada kode ini setelah URL semua ditulis maka url selanjutnya akan ditulis pada baris baru. Sehingga dapat dilihat berikut output dari variabel textToSave.

Kemudian untuk kode baris kedua dengan nama variable hiddenElement yaitu data URL yang telah dibuat array diubah menjadi hidden element dengan tagName a. Untuk kode baris ketiga digunakan untuk mengubah data URL array menjadi text.

Selanjutnya untuk baris keempat, atribut target digunakan untuk menentukan tempat untuk membuka dokumen seperti _blank membuka dokumen yang terhubung di jendela atau tab baru, _self membuka dokumen dalam bingkai yang sama seperti yang diklik (ini adalah default), _parent membuka dokumen dalam bingkai induk, _top membuka dokumen di seluruh jendela, dan framaame membuka dokumen dalam bingkai bernama.

Kemudian untuk atribut download pada baris kelima digunakan untuk menentukan bahwa target akan diunduh saat pengguna mengeklik hyperlink. Atribut ini hanya digunakan jika atribut href disetel. Nilai atribut akan menjadi nama file yang didownload. Tidak ada batasan pada nilai yang diizinkan, dan browser akan mendeteksi secara otomatis ekstensi file yang benar dan menambahkannya ke file (.img, .pdf, .txt, .html, dll.). Kemudian untuk kode terakhir digunakan untuk mengeksekusi atau mendownload hiddenElement.

kita telah mempunyai file urls yang telah didownload, kemudian menggunakan program python untuk mendownload gambar dari masing – masing urls. Dalam program python ini menggunakan library request.

Packages atau module yang digunakan yaitu request untuk mendownload gambar yang ada di urls, kemudian argsparse digunakan untuk membuat argument menulis inputan kode, cv2 digunakan untuk membaca lokasi output gambar. Kemudian paket os digunakan untuk menyimpan gambar pada folder output yang sudah di tentukan. Dan yang terakhir imutils digunakan pada saat list file gambar pada folder output untuk dilakukan perulangan.

Selanjutnya, mengurai argumen baris perintah dan memuat urls dari disk ke memori. Urutan baris perintah parsing dilakukan pada baris 9-14 disini menggunakan dua parsing:
--urls : Path dari file yang berisi urls gambar yang dihasilkan oleh Javascript di atas.
--output : Path dari output untuk menyimpan gambar yang didownload dari Google Images.
Pada baris 18 digunakan untuk memuat setiap urls dari file ke dalam daftar, kemudian juga menginisialisasi sebuah counter, total, untuk menghitung file yang telah kami download. Pada baris 18 terlihat proses yaitu membuka parsing urls kemudian membaca file tersebut (.read()). Selanjutnya mengembalikan salinan string dengan karakter terdepan dan trailing yang dihapus (berdasarkan argumen string yang dilewati) (.strip()). Kemudian menghapus “\n” pada data urls.

Dengan menggunakan requests, disini hanya perlu menentukan urls dan timeout untuk download. kita mencoba mendownload file gambar ke dalam variabel, r, yang menampung file biner (bersama dengan header HTTP, dll.) dalam memori sementara atau biasa disebut RAM (Random Access Memory) ( Kode baris 25). Selanjutnya menyimpan gambar ke disk, hal pertama yang diperlukan adalah path dan nama file yang valid. Kode baris 28-29 menghasilkan path + filename, p, yang akan menghitung secara bertahap dari 00000000.jpg. kita kemudian membuat sebuah file pointer, f, menentukan path output, p, dan menunjukkan kita ingin menulis mode dalam format biner ("wb") pada kode baris 30. Selanjutnya, menulis isi file dari f (r.content) dan kemudian menututup file (Kode baris 31 dan 32). Dan akhirnya, memperbarui jumlah total gambar yang diunduh pada kode baris 35 dan 36). Jika ada kesalahan yang ditemukan di sepanjang proses pengunduhan, maka sebuah pesan dicetak ke terminal (Kode baris 39 dan 40. Kita akan mengulang semua file yang baru saja didownload dan mencoba membukanya dengan OpenCV. Jika file tidak bisa dibuka dengan OpenCV, maka akan dihapus dan dilanjutkan. Ini tercakup dalam blok kode berikut:

Saat melakukan perrulangan setiap file, akan diinisialisasi delete ke False (Kode baris 45). Kemudian kita akan mencoba memuat file gambar di Kode baris 49. Jika gambar dimuat sebagai None, atau jika ada pengecualian, maka akan menyetel delete = True (Kode baris 53-54 dan kode baris 58-60). Alasan umum gambar tidak dapat dimuat yaitu kesalahan selama unduhan (seperti file yang tidak diunduh sepenuhnya), gambar rusak, atau format file gambar yang tidak dapat dibaca OpenCV. Terakhir jika flag delete diset, kita panggil os.remove untuk menghapus gambar pada kode baris 63-65.
Setelah mengetahui bagaimana program berjalan selanjutnya kita akan praktekkan bagaimana melakukan crawling images di google images.
1. Setelah memasukkan query di google image search (penghapus), kemudian kita scroll sampai gambar mana yang mau kita download.
1. Setelah memasukkan query di google image search (penghapus), kemudian kita scroll sampai gambar mana yang mau kita download.

2. Selanjutnya kita buka developer tools (pojok kanan > more tools > developer tools) disini saya menggunakan google chrome.

3. Open js_console menggunakan notepad ++ atau text editor yang lain, kemudian Copy 1 persatu code yang ada didalamnya ke console javascript di google chrome.
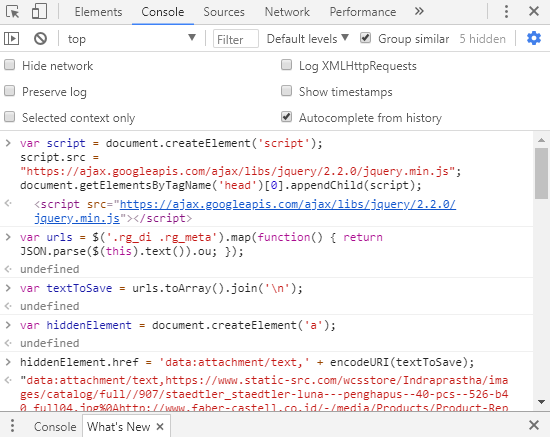
4. Setelah urls terdownload, selanjutnya mendownload gambar menggunakan python program. Tetapi sebelum itu kita buat folder images untuk output programnya. Jalankan program dengan perintah python download_images.py --urls urls.txt --output images/

5. Tunggu hingga download selesai dan cek folder images, gambar telah ter download.

Terimakasih telah berkunjung ke artikel kali ini semoga bermanfaat bagi kita semua.
Crawling Images In Google Images
 Reviewed by Jimmy Pujoseno
on
March 25, 2018
Rating:
Reviewed by Jimmy Pujoseno
on
March 25, 2018
Rating:
Reviewed by Jimmy Pujoseno
on
March 25, 2018
Rating:




 3x3 dan 3x4 Menggunakan Excel")

min kok sekarang data attachmentnya jadi this site can't be reached, ini apa yang harus diubah yah? trims
ReplyDeletemin ko error ya kodingannya?
ReplyDelete